class: center, middle, inverse, title-slide # Reproducible Housing Analysis ## Toward reproducibility, transparency and adaptability ### Jens von Bergmann ### 2018-12-10 --- # Goals for this talk: 1) What does reproducibility mean today? 2) Showcase some tools to work with [census](https://mountainmath.github.io/cancensus/index.html), [CMHC](https://github.com/mountainMath/cmhc), [cansim](https://mountainmath.github.io/cansim/index.html) and other public data 3) Highlight some obstacles and data gaps 4) Advocate for a culture of collaborative data analysis --- # So much data, so little time Data analysis and communication of results take a lot of time. So I favour workflows that facilitate and greatly speed this up while increasing *transparency*, *predictability* and *adaptability*. I want to showcase some of these tools dealing with * Property Level Data * Census Data * CMHC Data * CANSIM Data * ... --- # Property Level Data Property level data lets us explore civic questions at the individual property level. Great detail, but missing demographic variables. Also, sketchy coverage, lots of important variables aren't publicly accessible. Comprehensive data is available to researchers and deep-pocket private interests, but NDAs create barriers. Because of barriers to access we are mostly stuck at doing simple descriptive analysis visualizations. Examples: * [Assessment (and related) Data](https://mountainmath.ca/map/assessment) * [Teardown Index data story](https://mountainmath.ca/teardowns) * [Tax Density](https://mountainmath.ca/assessment_gl/map) * [Houses and Dirt Explorer](https://mountainmath.ca/assessment/split_map) * Listings data ??? Sadly, most useful data is not publicly available. Can be accessed for research through cumbersome process and results can't be shared unless dropping detail and aggregated to high level. --- # Data infrastructure Just as important as access to data is data infrastructure. Good API access to data is critical to efficiently working with data, and it provides a great starting point of collaborative analysis. APIs come at different levels of usefulness: -- 1) Standardized, versioned and authoritative APIs - Ideally APIs have clear data protocols that clients can rely on. They are versioned so that changes to API don't break infrastructure that builds on older versions. And they are implemented by the entity generating the data, providing an authoritative source. - The new StatCan NDM is standardized and authoritative, but not fully versioned. -- 2) Third party APIs, - When APIs are not available, a third part may mirror the data and implement an API. CensusMapper is one example. -- 3) Pseudo-APIs. Data available, but it requires clicking through a website, accumulating cookies and submitting web forms to download data. - One can implement a pseudo-API that wraps this process and provides a clean interface to access data. - CMHC is an example, and my *cmhc* R package wraps this. --- # Examples of data infrastructure CensusMapper is my answer to the inaccessibility of census data by non-experts. It allows instant and flexible mapping of census data. Canada wide. Maps can be narrated, saved and shared. By anyone. --- background-image: url("https://doodles.mountainmath.ca/images/net_van.png") background-position: 50% 50% background-size: 100% class: center, bottom, inverse # <a href="https://censusmapper.ca/maps/731" target="_blank">CensusMapper Demo</a> ??? Lots of hidden features too that aren't accessible to general public. Don't have the resources to make them more user-friendly and release to public free to use. --- # Maps aren't analysis CensusMapper has APIs to facilitate deeper analysis. Open for all to use. [`cancensus`](https://github.com/mountainMath/cancensus) is an R package that seamlessly integrates census data into data analysis in R. Let's try and understand the effects of the net migration patterns by age on the age distribution. ??? While we do need better data, we don't make good use of the data we already have. What's needed most is analysis. --- # Age pyramids How does the net migration effect the age distribution in each municipality? ```r plot_data <- get_age_data('CA16',list(CSD=c("5915022","5915004","5915055"))) %>% rename(City=`Region Name`) ggplot(plot_data, aes(x = Age, y = Population, fill = Gender)) + geom_bar(stat="identity") + facet_wrap("City",nrow=1, scales="free_x") + age_pyramid_styling ``` <!-- --> ??? Explain how net migration patterns lead to different age distributions. --- background-image: url("/images/api_tool.png") background-position: 50% 50% background-size: 100% class: center, bottom, inverse # <a href="https://censusmapper.ca/api" target="_blank">CensusMapper API Demo</a> --- # Value of API access * Census data is already openly available, but API access makes it easy to work with. * Bulk census data is unwildly, hard to share and often gets manually pre-processed which breaks reproducibility. * [`cancensus`](https://github.com/mountainMath/cancensus) is an R wrapper for these APIs that makes analysis reproducible, transparent and adaptable and accessible to everyone. -- .center[**Well, maybe not everyone. But everyone here.**] --- # Non-census data CMHC provides great housing-related data. It's a pain to download, so I built an [pseudo-API in R](https://github.com/mountainMath/cmhc). ```r cmhc <- get_vacancy_rent_data(c("Vancouver","Toronto","Calgary","Winnipeg"),"CMA") ggplot(cmhc, aes(x = Year, y = Rate, color = Series)) + vanancy_plot_options + geom_line() + geom_point() + facet_wrap("city", ncol=2) ``` <!-- --> ??? CMHC has recently made finer data available. Sadly no APIs, but we can hack their data portal to speed up analysis. So we built a pseudo-API to consume it. This graph shows the primary market vacancy rate and the fixed-sample rent change on the same axis. We note the clear inverse relationship between the two, with sometimes strong responses in non rent-controlled Calgary. And yes, rents do drop when the vacancy rate is high. --- # CANSIM How to add more context to this? What macro-economic factors drive rent and rental vacancy rates? StatCan provides data we can fold in for deeper insights. ```r data <- get_cansim("14-10-0325") %>% pre_process ggplot(data,aes(x=Date,y=VALUE,color=GEO)) + geom_line(alpha=0.3) + geom_smooth(se=FALSE) + job_vacancy_theme ``` <!-- --> --- # Rents and income in Vancouver <!-- --> --- # Next steps in data infrastructure As our depth of data processing and analysis increases, we start to need a shared infrastructure for derived data. -- * Build an infrastructure for sharing custom data extracts, even when they are not fully standardized. For example custom census tabulations. * For complex models where training is computationally intensive or some of the training data is sensitive we can share the model kernel or other model output. * Build out statistical tools to deal with common data issues. Examples are [tongfen](https://github.com/mountainMath/tongfen) to make census geographies and data comparable across census years, or more robust ecological inference models for estimating individual level correlations from aggregate data. --- # Some concrete ideas for needed data infrastructure - Mixing in real estate listings data - Keeping the census fresh - Build out [tongfen](https://github.com/mountainMath/tongfen) to all census geographies and expand API coverage for census years. - Advanced ecological inference models --- # Rental Listings Data Rental listings data is another data source that can augment survey and census data. ```r yvr_cts=get_census(dataset = 'CA16',regions=list(CMA="59933"),geo_format='sf',level="CT") listings_data <- get_listings(s_time,e_time,st_union(yvr_cts$geometry),beds=1,filter = 'unfurnished') aggregate_listings <- aggregate(listings_data %>% select("price"),yvr_cts,median_rent) ggplot(aggregate_listings,aes(fill = price)) + geom_sf(size=0.1) + rental_map_theme ``` <!-- --> Rental listings data is messy, but provides fine-grained and real-time information. Can augment CMHC survey and census data to provide more timely insights into rental market. ??? Only showing data for areas with at least 10 listings. --- # For sale listings data Listings data is great to complement public data, but vague legal framework prevents easy sharing of data, analysis and results. 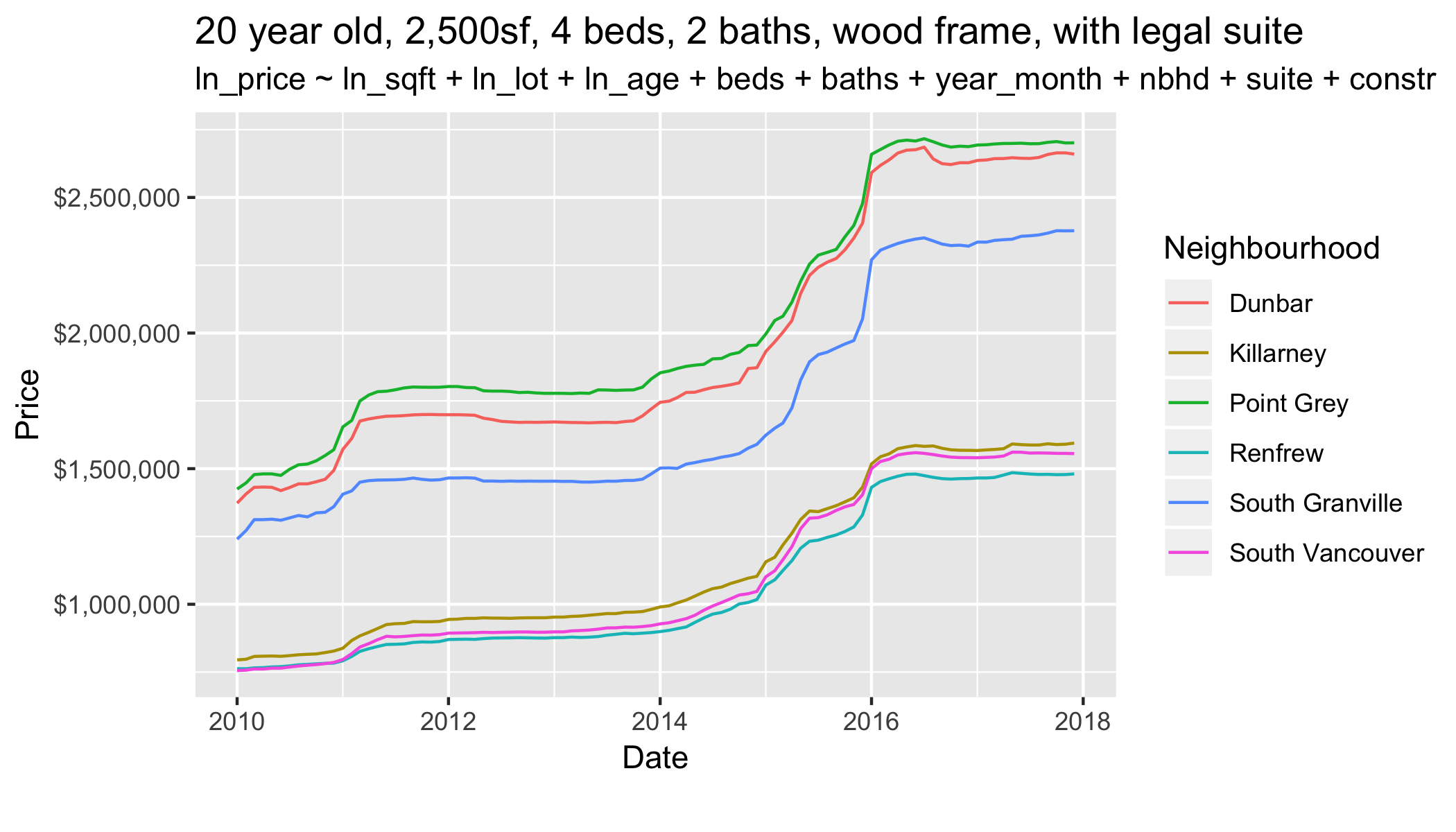 We are still working off of 20th century models and concepts. HPI is a good all-purpose tool, but too coarse to be used in most analysis. ??? Non-open nature of this data limits how this data can be used and makes collaborative approaches very hard. --- # Keeping the Census fresh The 2016 census data is still quite up to date. But the clock is ticking, how can we keep it fresh? <!-- --> CANSIM data includes census undercounts. We can use relative changes in CANSIM data to estimate changes in Census data. ??? A retroactive look. --- # Where in Vancouver did people move to? CMHC building data can tell us where people go, we can use past censuses migration data to model demolition rates and the demographics of the new units. <!-- --> ??? Mixing in concurrent data sources like CMHC and CANSIM can extend the useful life of census data. Data APIs designed to be easily integrated facilitate this. And APIs make it simple to update analysis when new data becomes available. --- # Reality Check Census and CMHC timelines of completions don't always line up. Demolitions explain part of that, as do slow move-ins in recent completions, and as issues in Census and CMHC data. <!-- --> ??? Estimate is reasonably good. There are some timing issues with completions close to the census. Single family areas see relatively many demolitions for each new built, should not be hard for a model to learn to estimate. --- # Mixing data sources Mixing data from different sources is tricky. Sometimes we want to make individual-level inferences from aggregate data. Classical example is inferring minority voting and turnout from aggregate eligible voter and voting results data. In the context of housing data it could be inferring data on property usage by mixing Airbnb scrapes, census data, electricity usage data and other administrative sources. These datasets can't be mixed at the individual property level. --- # A Toy Example Consider an example where we know the answer. Take the number of households spending more than 30% of income on shelter in each census tract in Metro Vancouver, as well as the share of Owner and Tenant households. We want to know what share of Owner and Renter households each spend more than 30% of income on shelter. <!-- --> --- # Ecological Inference Ecological inference builds a distribution over the space of our quantities of interest, the share of owners `\(\beta^w\)` and the share of renters `\(\beta^b\)` spending more than 30% of income on shelter. <!-- --> --- <!-- --> Tenants spending > 30% of income on shelter: 41%, Goodman Reg: 51.5%, Actual: 43.5% Owners spending > 30% of income on shelter: 26.8%, Goodman Reg: 20.4%, Actual: 25.4% --- # Mapping the Residuals A geographic check of the residuals reveals where we went wrong. In regular examples we don't have this information and have to rely on other tests to understand the presence of biases in our model and refine it. <!-- --> --- # Reproducibility, Transparency, Adaptability We need to adopt a more collaborative approach to understanding civic issues. .pull-left[ ### Notebooks A data Notebook is a document that integrates explanatory text and data analysis. In its crudest form this could be an Excel spreadsheet with embedded comments. At the other end of the spectrum are R or Python Notebooks. In fact, this presentation is an R notebook and [lives on GitHub](https://github.com/mountainMath/presentations/blob/master/reproducible_housing_analysis.Rmd). It contains all the code to reproduce the graphs in the presentation. ] .pull-right[ ### APIs In order to be reproducible, any analysis should ship with code and the data. But that's not very adaptable. To be adaptable, the data should come through APIs. That way one can easily make changes that requires slightly different data, e.g. use related census variables, other time frames or geographic regions. Analysis can automatically update as new data becomes available. ] -- .center[**Should become standard as base for public policy.**] -- I will leave you with some quiz questions. ??? This is key to building an ecosystem of people and groups that collaborate to advance understanding of civic issues. Opening up your analysis for everyone to see and pluck apart might be uncomfortable at first, but it's essential to take the discussion to the next level. It increases transparency and trust, and allows others to build on your work. --- # Question 1 Has affordability in the City of Vancouver gotten better or worse? -- <!-- --> Diverging narratives that need to be reconciled: At ecological level, it looks like things got worse. At individual levels, it looks like like they got better. --- # Question 2 Which city has higher incomes, Toronto or Vancouver? -- <!-- --> --- # Question 3 What share of Toronto and Vancouver residential properties are owned by owner-occupiers, investors living in Canada and investors living abroad? -- <!-- --> --- # Question 4 Which Canadian CMA has the highest share of renter-occupied apartment condos? Which has the highest share of empty condos? -- 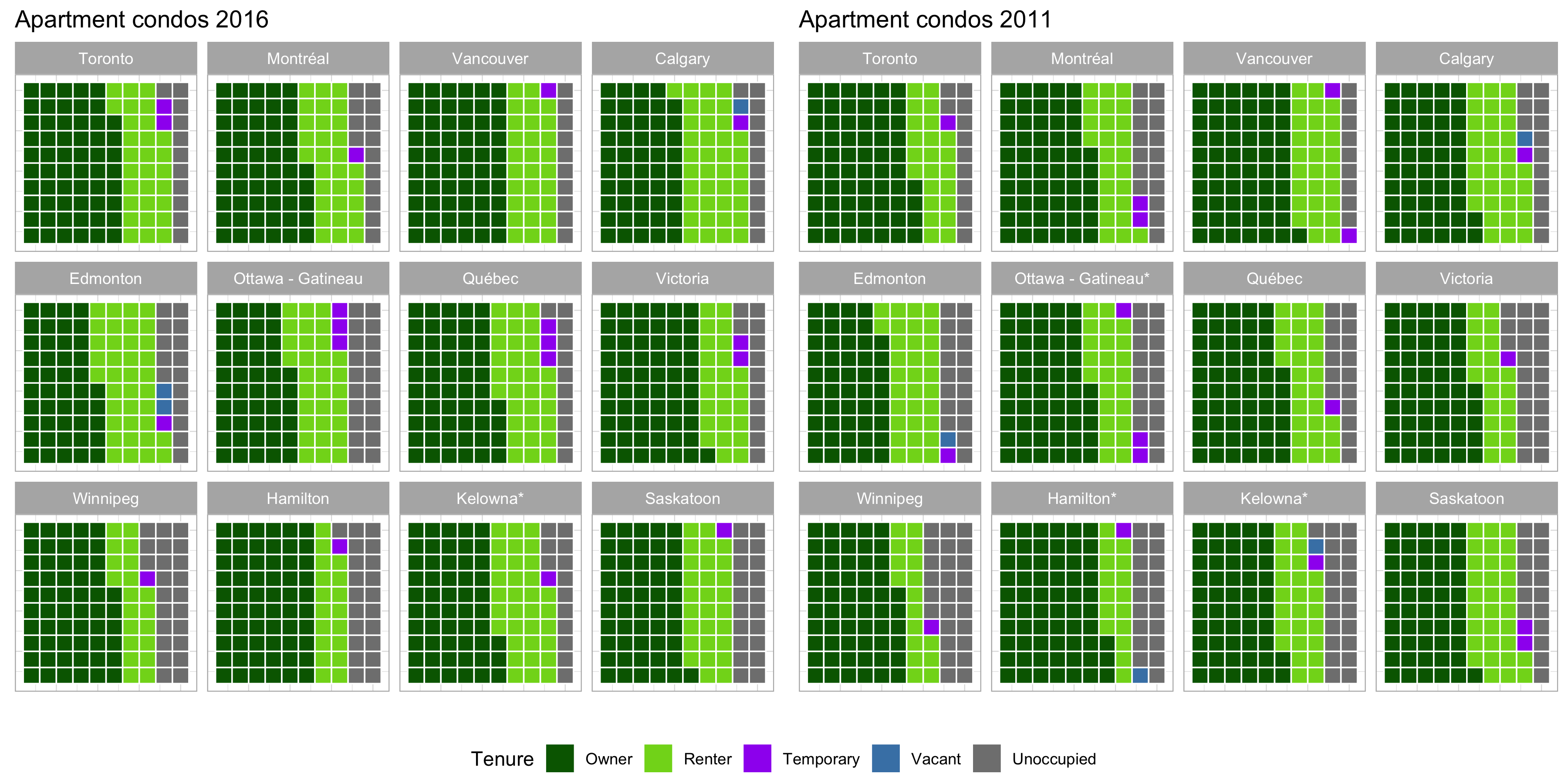 --- class: center, middle Thanks for bearing with me. These slides are online at https://mountainmath.ca/reproducible_housing_analysis/reproducible_housing_analysis.html and the R notebook that generated them includes the code that pulls in the data and made the graphs and [lives on GitHub](https://github.com/mountainMath/presentations/blob/master/reproducible_housing_analysis.Rmd). ??? Our discussion rarely move beyond presenting a simple quotient. We need to move beyond viewing the world through single census variables or simple percentages and dig deeper into the very complex issues we are facing.